Widok szczegółów pracy
Widok szczegółów pracy zawiera podstawowe informacje identyfikujące pracę i statystyki oraz wyniki analizy antyplagiatowej.
Spis treści
Funkcjonalności
Zaraz po dodaniu dokumentu na stronie wyświetla się jego metryka wraz z wyliczonymi statystykami słów występującymi w pracy. W prawym górnym rogu znajduje się aktualny status pracy. Jeśli jest inny niż sprawdzony - wyników z bazy jak również wyników z NEKST może nie być. W takiej sytuacji należy odczekać chwilę a następnie odświeżyć stronę.
Metryka pracy
Metryka pracy zawiera metadane, które pozwalają ją zidentyfikować w systemie. Zawiera również informacje potrzebne do wygenerowania raportu z usługi antyplagiatowej.
Zawartość
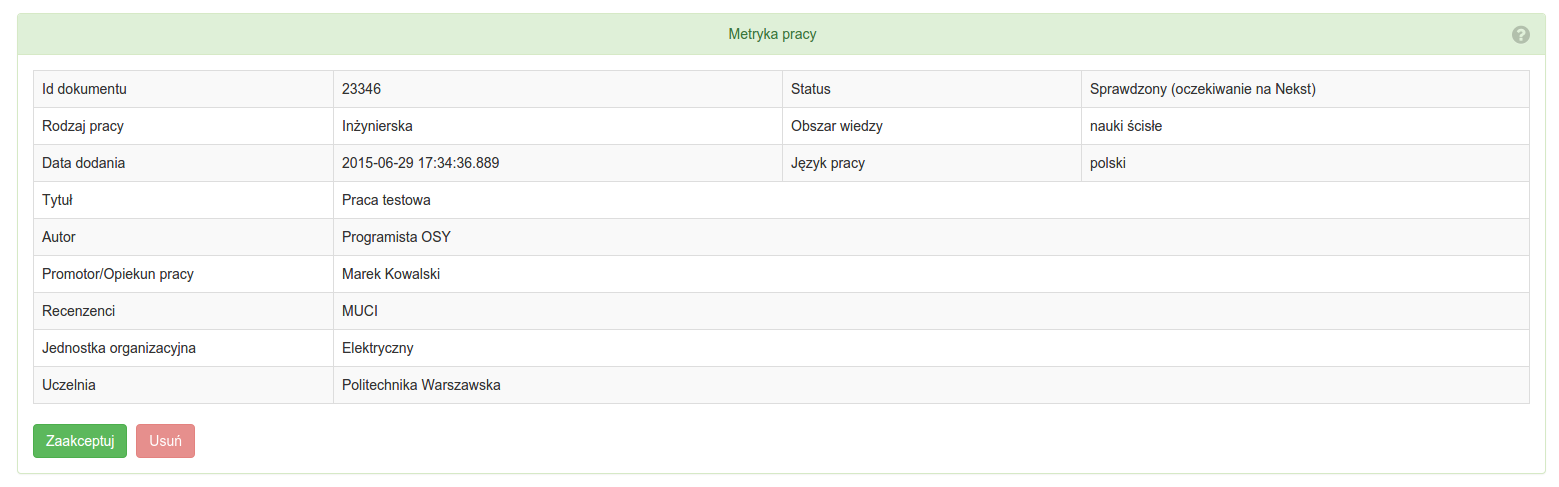
Matryka pracy zawiera:
- Dane systemowe:
- ID pracy w systemie OSA.
- Data dodania do OSY.
- Status pracy.
- Dane informacyjne:
- Rodzaj pracy.
- Tytuł.
- Autor.
- Promotor/Opiekun pracy.
- Recenzenci.
- Jednostka organizacyjna.
- Uczelnia.
- Obszar wiedzy.
- Język pracy.
Funkcjonalności
Dodatkowo (zależnie od statusu pracy) pojawiają się przyciski na dole, które umożliwiają podjęcie pewnych akcji. Tymi akcjami mogą być:
- Akceptacja pracy.
- Dezaktywacja pracy.
- Usunięcie pracy.
To czy dana funkcja się wyświetli zależy od aktualnego statusu pracy jak również od praw jakie posiada dany użytkownik w systemie OSA
Statystyki słów
Statystyki słów są częścią widoku szczegółów pracy, zawierającą statystykę słów zawartych w dokumencie.
Zawartość
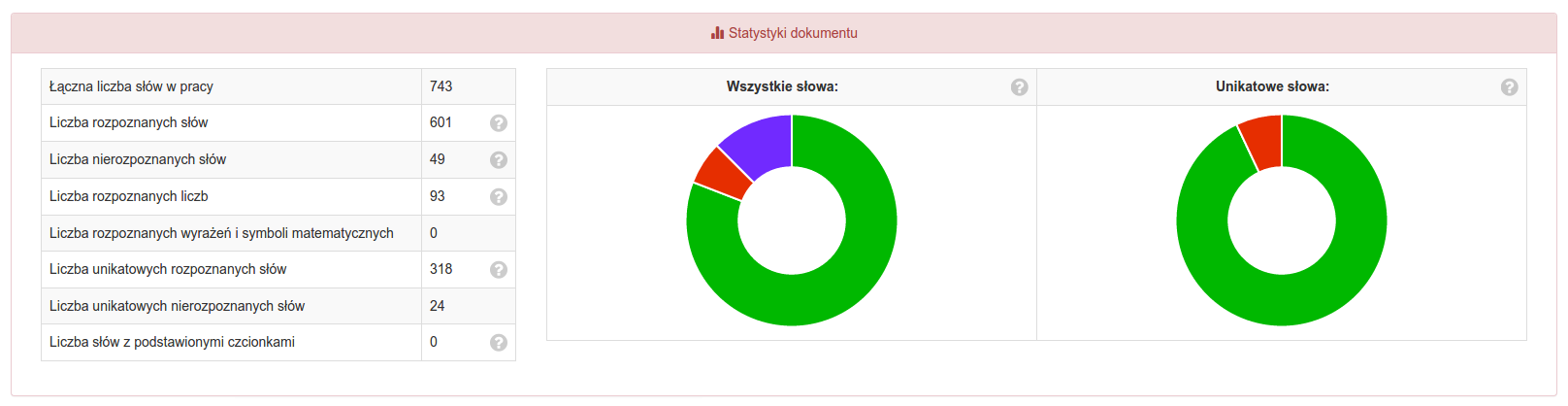
Na statystyki słów skłądają się:
- Liczba wszystkich słów w pracy, w tym:
- Liczba słów rozpoznanych jako słownikowe (pochodzące z języka polskiego).
- Liczba nierozpoznanych słów jako słownikowe.
- Liczba rozpoznanych liczb.
- Liczba rozpoznanych wyrażeń i symboli matematycznych.
- Liczba unikatowych rozpoznanych słów.
- Liczba unikatowych nierozpoznanych słów.
- Liczba słów zawierających podstawienia czcionek (w tej statystyce liczone jest również jako słowo rozpoznane).
- Wykresy tortowe, które obrazują graficznie wymienione wyżej dane (po najechaniu myszką na wykres, pokazywane są podpowiedzi)
Uwagi
Liczba unikatowych słów - jest to liczba słów w całej pracy z tym, że jeśli dane słowo wystąpiło kilka razy - jest liczone tylko raz. Słowo z podstawioną czcionką - jest to słowo co najmniej 3 literowe posiadające znaki spoza alfabetu polskiego, które system zdekodował jako słownikowe po próbie deszyfracji. Liczone jest ono również w statystyce jako wyraz rozpoznany
Wynik sprawdzenia antyplagiatowego
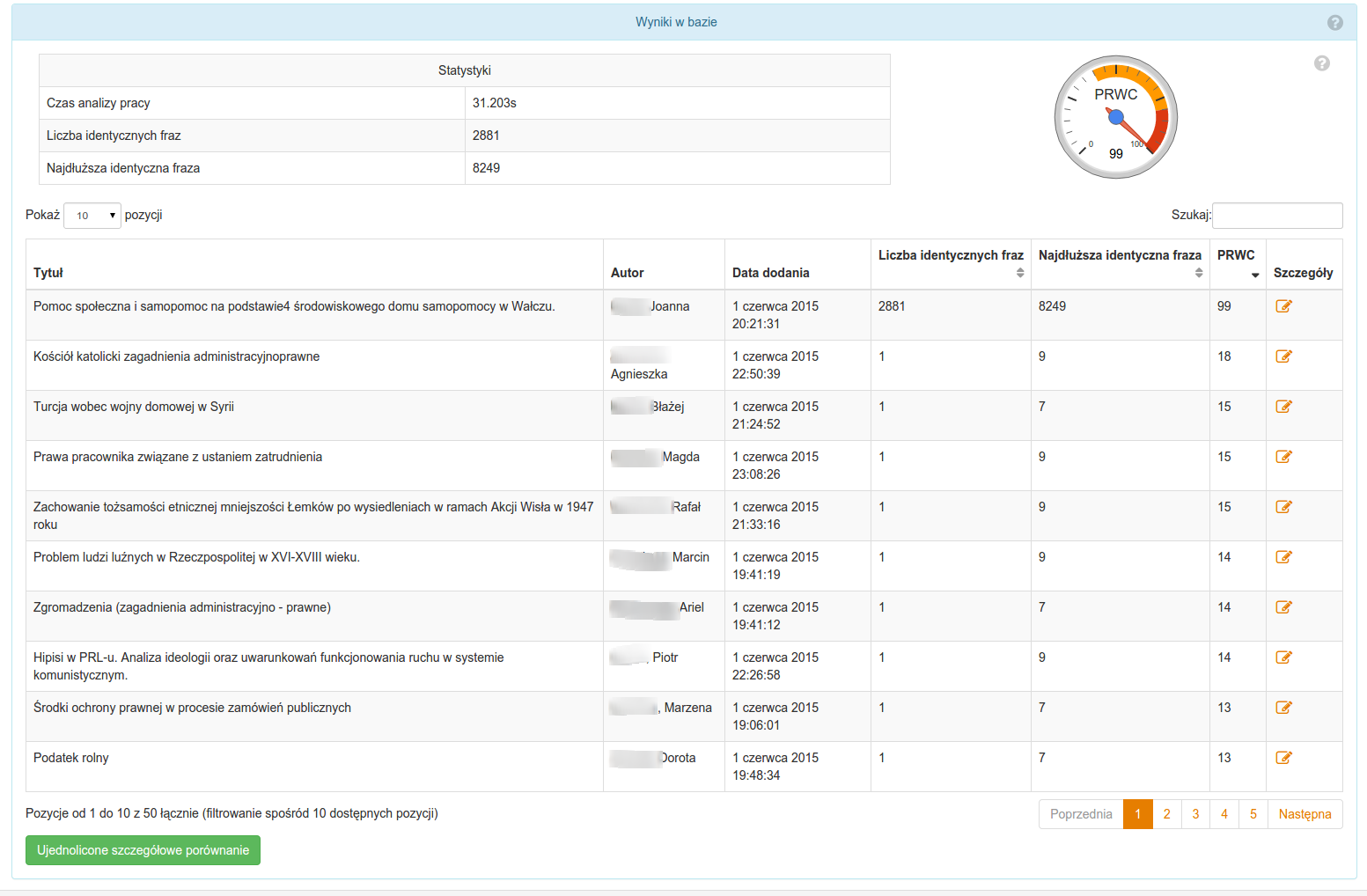
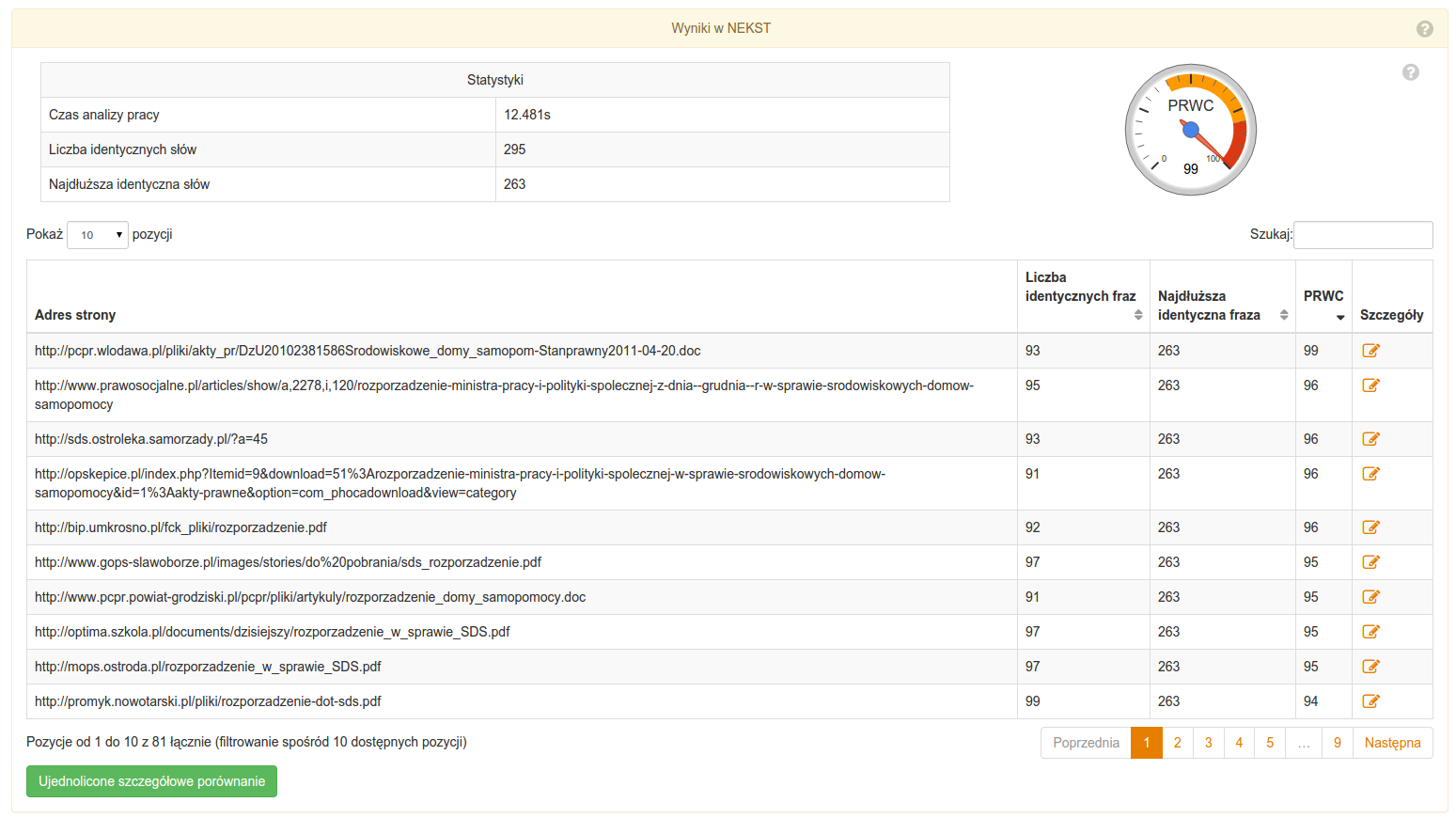
Wyniki z bazy i Nekst zawierają rezultaty analizy antyplagiatowej danej pracy. Należy zauważyć, że oba te wyniki są obliczane oddzielnie i żaden z nich nie jest związany ani zależny od drugiego.
Wyniki z bazy zawierają analizę zapożyczeń pracy względem wszystkich prac z bazy referencyjnej. Baza ta zależnie od uczelni może mieć rozmiar od kilkudziesięciu do kilkuset tysięcy prac.
Wyniki z NEKST zawierają analizę zapożyczeń z polskiego Internetu. Baza ta ciągle się powiększa i aktualizuje, jej liczebność przekracza 0.6 miliarda stron.
Uwaga! Od wersji 4 obie tabele zostały złączone w jedną.
Zawartość
Każdy z wyników prezentowany jest w formie tabelarycznej. Prezentowane są tam następujące informacje:
- Tabela statystyk
- Czas analizy pracy - mierzony w sekundach.
- Liczba identycznych fraz - jako najwyższy wynik z tabeli zapożyczeń (prezentowanej na dole).
- Najdłuższa identyczna fraza - jako najwyższy wynik z tabeli zapożyczeń (prezentowanej na dole).
- Wykres PRWC - jako najwyższy wynik z tabeli zapożyczeń (prezentowanej na dole).
- Tabela zapożyczeń
- Tytuł/Link dokumentu.
- Liczba identycznych fraz dla pary dokumentów (porównywany i znaleziony).
- Najdłuższa identyczna fraza dla pary dokumentów (porównywany i znaleziony).
- Wskaźnik PRWC.
- Link do szczegółowego porównania.
- Link do ujednoliconego szczegółowego porównania.
Uwagi
- Zawsze należy zapoznać się z rozwinięciem zakładki "Treść pracy" znajdującej się na dole widoku szczegółów pracy.
- W przypadku wyników z NEKST - prezentowana jest maksymalne 100 najwyższych wyników. W przypadku wyników z bazy limit ten nie obowiązuje.
- Wyniki z NEKST często zawierają zapożyczenia ze stron Wikipedii, jednakże często na liście widać wyniki z klonów Wikipedii.
- Wyniki w tabelach można sortować po miarach podobieństwa.
- Czas analizy z bazy zależy od wielkości bazy referencyjnej, wielkości dokumentu sprawdzanego oraz liczby prac czekających na sprawdzenie w kolejce.
- Czas analizy z NEKST zależy jedynie od kolejki prac oczekujących (algorytm nie jest wrażliwy na liczbę prac w bazie). Przeciętnie czas sprawdzenia w NEKST to ok. 2 sekundy. Pozostały czas to praca wynikająca z wysłania i odebrania wyników, wyliczenia statystyk itp.
Treść pracy

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Na dole strony znajduje się zwinięty pasek treści pracy. W momencie jego kliknięcia pasek rozwija się, a w tle pojawia jest treść z wyróżnieniem na żółto słów nierozpoznanych oraz wyróżnieniem na czerwono słów z podstawieniami czcionek.